Raft
论文笔记
前置知识和概念:
- 共识算法常被用来确保每一个节点上的状态机一定都会按相同的顺序执行相同的命令, 并且最终会处于相同的状态(复制状态机模型)。它允许其中的节点出现故障后,整个系统仍然能保持运作,也就是高可用特性。具体来说,共识算法解决数据存储下的一致性问题,提供容错机制。
这里不得不提到复制状态机:多个节点在相同的初始状态下,执行相同的输入,那么最后的状态一定是相同的。这就解决了副本之间的一致性问题。在 Raft 算法中,leader 通过发送 log entry 请求到所有的 follower 节点,节点按照日志记录依次执行,那么最后的状态就是一致的。
- 节点的状态只会有 follower,candidate,leader。如果节点之间没有收到 leader 的心跳,那么就会进入 candidate 状态,向所有节点并发发送请求包和响应请求。经过一次或多次的选举,选出 leader。
- 时间按照任期进行划分,每次开启新的任期,term+1
- 通信 rpc 类型包括:请求投票(投票选举 leader)和追加条目(由 leader 发起,用来追加日志条目和心跳机制)
- 还是论文当中的核心用几个问题来拆分,分别是以下问题:
A1:Raft 算法是如何避免脑裂问题的?
从一个数学的角度,过半票决是怎么解决脑裂的?总结来看,脑裂问题主要需要解决单一性、一致性问题。
- 单一性:为了保证不同网络分区总共也只能有一台主服务器,那么就要求服务器的数量是奇数的,保证分区服务器数量不对称,从而达到要求:在任何时候为了完成任何操作,你必须凑够过半的服务器来批准相应的操作 。这样保证过半的前提下,奇数服务器确保一个 leader
- 一致性:这更有趣,以选举为例,每一个操作对应的过半服务器,必然至少包含一个服务器存在于上一个操作的过半服务器中。也就是说,任意两组过半服务器,至少有一个服务器是重叠的。新 leader 依靠这个至少一台存在于旧 leader 的服务器,就能够知道旧 Leader 使用的任期号(term number)和任何旧 Leader 提交的操作。这是保证一致性的关键。
A2:Raft 作为一个共识算法,怎么和应用层接入?
Raft 集群当中主要有两个接口一个是 key-value 接口,另一个是函数调用 Start 接口。key-value 层用来转发客户端请求的接口,Start 函数主要执行日志复制的过程。需要注意的是,key-value 接口向 Raft 层发送请求的时候,并不是同步的,客户端可以不用等待一个请求被确认 commit 之后在发送下一个请求,大量的请求同时发送是常见的。直到 Start 函数执行完毕后,Raft 层通过 applyCh 通道确认 key-value 已经成功执行,可以向客户端返回了。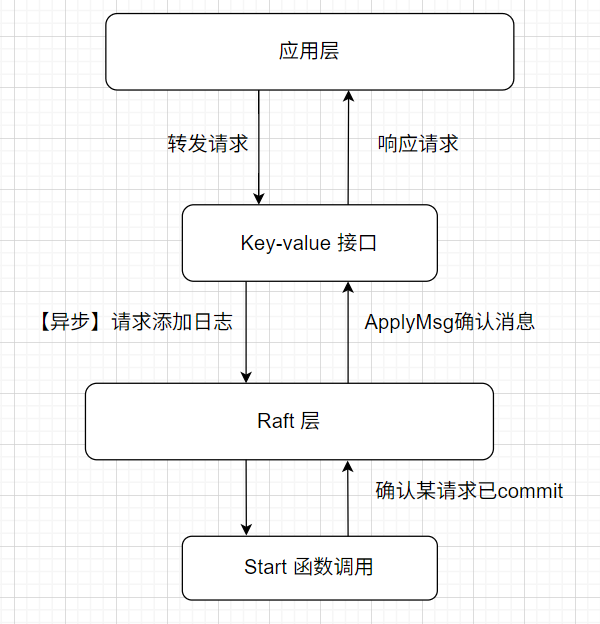
A3:raft 集群当中的 commit、取消、和过半哲学?
在 A1 问题中,为了避免脑裂解释了过半是怎么保证一致性和单一性的。同时还有一些别的
A4:Raft 是怎么解决多副本之间协调一致的问题?
采用 leader 选举的方法,有多个节点当中的 leader 决定 client 数据写入其他节点的顺序(类似于上面的 GFS 的主 primary ,但不同的是 GFS 是 master 指定的,而 Raft 是节点之间自主选举产生,依靠 RPC 发送日志条目)。 follower 没有接收到心跳后,进入 candidate 状态,首先会把自己的任期 term+1,其次给自己投票,然后并发向所有的节点发送投票请求 RequestVote RPC。节点接收到投票请求,会给出一个响应,如果请求的 term >= 自己的 term,根据 ”先来先服务“ 的原则投出票。如此执行,直到有节点最先得到超过半数票,立即切换状态成为 leader,向所有其余节点发送心跳包,而其它节点收到心跳之后状态从 candidate 转换成 follower。至此,新的 leader 产生。
❓ 那么这样是不是会导致很多节点同时选举,票数分散?可能,但仍然要考虑每个节点意识到自己 ”可以成为 candidate“ 时机不同,网络的快慢,结点的分布都可能成为优势。
注:实际编码中用了 rand 函数,让每个节点每次选举时间是不同的
mit6.824 raft实验部分
Lab2B
A0:日志复制怎么保证一致性特性?
流程:
- Leader 将日志条目追加到本地日志,并通过
nextIndex[]向各 Follower 发送。 - Follower 接收到日志条目,并通过
matchIndex[]反馈成功复制的最大日志索引。 - Leader 通过
matchIndex[]判断日志条目是否被大多数节点复制,如果满足法定人数,则更新commitIndex,并通知所有节点提交该条目。(peer 在下一次的心跳或者 append entry 中 leaderCommit 检查是否可以更新) - Follower 更新
commitIndex和appliedIndex,将已提交的日志条目应用到本地状态机。[!quote] Raft 算法里面的一些结构体说明。
- commitIndex :表示当前已被提交的日志条目的索引,在 follower leader 中均有。更新是在 Leader 将日志条目复制到大多数节点之后,由 Leader 来更新。
- appliedIndex :表示前已应用到本地状态机的日志条目的最大索引。leader 确定了 commit index 之后,确认超过半数就可以写入到本地状态机了,即更新。大多数情况是两者相等,如果 appliedIndex < commitIndex ,那么节点会继续应用直至相等。
- 日志号和任期号同时配合才能确定一个日志, 避免 leader 没处理完挂掉之后,部分副本上有日志,而新选举的 leader 没有,但是 term 更大更权威,所以可以删掉那些过期的日志,毕竟也没有提交写入
A1:为什么需要 rf.replicatorCond ?
这是优化的部分,比较难懂。首先这是每一个 server 维护了条件变量的数组(每一个 server 对应一个条件变量 replicatorCond 数组,而不是一个条件变量),当 server 被 make 函数启动时,replicatorCond 是一直在循环中 wait 的,直到他成为 leader 并且检查到某一个 follower 没有跟上自己的最新日志,那么就会唤醒去执行 replicaOneround。
那么这个条件变量由谁来唤醒呢?是上层应用调用 start,进一步 broadcastHearbeat() 提醒:成为 leader 之后,复制日志的时候要给每一个 peer 提醒,replicatorCond[peer].Siganl() 函数派上用场。如何优化的,即使被唤醒后,可能某个 peer 的 commitindex 再重复发送日志的过程中并没有变化,即不满足 rf.commitindex[peer] < rf.getlastlog().index 那么就没必要给这个 peer 也发送,节省了 RPC 通信
1 | |
A2:日志复制的工作机制
上层应用调用 start() 对 leader 做了以下修改,后续的复制由此事件驱动:
append(rf.logs, newEntry)修改 logs 数组,从而 getlastlogIndex 也变化rf.commitIndex, rf.nextIndex[rf.me] = newEntry.Index, newEntry.Index+1
整个过程的核心是 replicateOneRound 函数,它封装了三个核心操作:生成请求 request–generateAppendEntryRequest;RPC 调用 follower 的 AppendEntries ;处理返回响应。 上层调用 appendEntry 和 leader 。心跳都会生成请求,这里生成 request 都用了一个函数统一,核心在于生成 entry 的时候copy(entries, rf.logs[nextlogIndex-firstIndex:])。如果是心跳包,那么 peer 节点的 nextlogIndex == leader.lastlog.index 所以 entry 空;如果是 append entry 那么 peer 节点的 nextlog.index 就会 < leader.lastlog.index 从而把每一个节点需要的日志都精准地复制下去。这样就实现了日志复制和心跳的统一。
接下来关注一下复制过程当中非常核心的几个状态:更新 leader/peer 的 commitIndex、提交到状态机、日志冲突回溯。
- leader 当客户端上层调用传递了一个指令,leader 就会把这个指令包装成一个日志添加到自己的日志数组当中,立即更新 commitIndex。这里可以理解成 leader 立刻收到了来自自己的日志复制请求并接受。
- peer 节点接收到 leader 的日志复制请求之后,检查合法性添加到日志数组,但这个时候并不会更新自己的 commit index,他会检查请求当中的 leader commit 如果 > 自己的 commit index 那么就会更新。所以可以说普通节点 commit index 的更新是要延迟于 leader 的。
- apply 状态: leader 节点在处理 peer 节点返回的响应如果发现大多数节点都已经成功的复制了日志,并且自己经过了检查——即将应用的日志的任期 == 自己当前的任期(背后有场景),那么就会提交到客户端上层应用。如果不满足条件就会保持 commitIndex 不动。成功唤醒应用线程,应用到状态机之后更新自己的 lastapplied。
- 普通节点同时还会另外开一个线程不断去检测自己的 commit index 和 last applied 两个指标如果一旦发现 commit index > last applied 那么就会更新并且提交于自己的状态机中(使用到了信号量,上面已详述)
- 日志冲突回溯:这个问题是为了解决leader 宕机导致的日志仅复制到了小部分节点上新的 leader 为了覆盖这部分旧的日志数据, 就会在 peer 节点的 prevlogIndex prevlog.term 检查,直到找到
request.prevlog.term == rf.log[index].term。这个问题背后出现的场景很复杂,也是日志复制过程中的边缘场景。
A3:Raft 的安全性保证
上面的介绍当中需要补充两点关于 Raft 对安全性保障的说明,首先 leader 节点在把日志应用到状态机的检查中,需要保证应用的 log.term == leader.current.term。为什么要做这样的约束呢? leader 节点再检查到某个日志被大多数节点所复制为什么不能够直接向上层应用提交状态呢?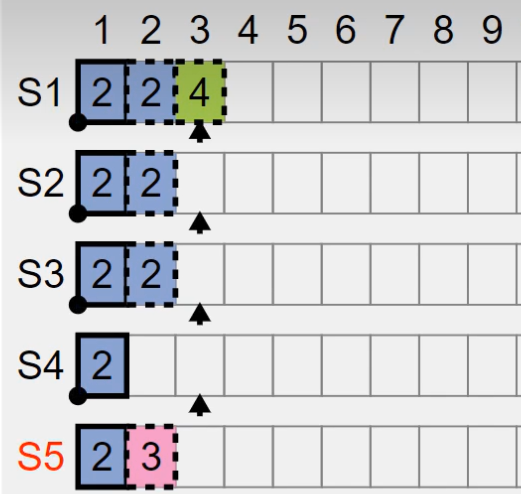
目的是为了 防止出现目前最新任期的日志主备切换,导致这种 log index 相同而任期不同的日志覆盖的情况 。上图中如果 S1 S2 S3 都应用日志二,那么当时的 leader 就会像上层调用反应日志二已经被应用到了大多数节点的机器上。但是如果 S5 此时当选成了 leader,就会凭借索引相同但任期号更大的日志 3覆盖掉原来日志 2 节点,这样就出现了客户端和实际机器集群当中的不一致状态。所以,Raft 要求 leader 节点要 新增一个自己的 append entry 才能够保护自己之前的日志能够提交。
第二个安全性问题是:为什么 leader 单点向客户端提交状态是可行的。换言之,为什么 leader 向客户端返回的应用日志索引之前的所有日志,都已经确保可以提交了?
这是由 request vote.lastlog.Index/term 保证,每一个 candidate 都会向其他所有的节点发送自己的最后日志的索引和任期号。这就要求了,如果他能够当选 leader,那么大多数的节点都认可他的最新日志。这也就避免了某一些 candidate 不符合大多数节点的日志状态,但是却当选 leader 的情况。也是 raft 中过半哲学能够维持的一致性体现