GFS课堂笔记
GFS
分布式目标是为了提升性能,同时机器过多可能会带来大量不定时出现的故障,因此需要有容错和监控系统。解决故障的方法是创建副本,那么又带来多个副本之间可能出现的不一致问题。
GFS 设计需要解决一些问题
文件怎么分散存储在多个服务器当中?
分割成 64MB 大小的 chunk 存储在不同机器下面,一个文件内容可能需要占用多个 chunk(gfs 设计准备 GB 级大小文件)。这个数字偏大,是为了减少 master 节点存储 chunk 信息,查询时尽量在少的 chunk 完成减少网络传输代价。
✅GFS 保证单点 master,原因是控制流和数据流分离,client 仅从 master 获取 chunk 的元数据信息,并不直接进行数据交互,这一点放在 chunkserver 与 client 中。另外,master 只持久化 file and chunk namespace、file 和 chunk id 的映射关系,至于 chunk 在哪个 server 当中并没有保存,因为可以和 chunkserver 通信得到一个 chunkserver 的所有 chunk 信息。
❓ 服务器发生故障怎么保证文件不损坏不丢失?
(高可用问题,在宕机之后仍能保证向外提供服务)
master 的高可用:master 和 元数据的高可用是一致的,采用主备复制的模式。master 更新/增加 namespace 或 改变映射关系首先写入日志,再将 wal 从 priamry master 发送到备用 master,直到备用 master 确认之后再更改主 master 的内存。而要识别 master 宕机需要共识算法。
chunk server 的高可用:通过 master 维持副本数量和副本之间的一致,并不遵循物理上 chunk server 主备一致性。GFS 设定只有三个 chunk 副本都保存了信息才算是写入完成,如果出现某个 chunkserver 宕机,还剩下两个副本可用。同时 master 可以在其他的 chunkserver 上新建副本,维持副本数目。
另外,master 需要将 chunk server 版本号保存起来,因为一旦 master 宕机,那么仅根据 chunk server 自己的版本号并不能确定哪个 server 是保存最新副本的安全 server
“当 Master 重启时,无论如何都需要与所有的 Chunk 服务器进行通信,因为 Master 需要确定哪个 Chunk 服务器存了哪个 Chunk。你可能会想到,Master 可以将所有 Chunk 服务器上的 Chunk 版本号汇总,找出里面的最大值作为最新的版本号。如果所有持有 Chunk 的服务器都响应了,那么这种方法是没有问题的。但是存在一种风险,当 Master 节点重启时,可能部分 Chunk 服务器离线或者失联或者自己也在重启,从而不能响应 Master 节点的请求。所以,Master 节点可能只能获取到持有旧副本的 Chunk 服务器的响应,而持有最新副本的 Chunk 服务器还没有完成重启,或者还是离线状态(这个时候 Master 能找到的 Chunk 最大版本明显不对)
因为 Master 从磁盘存储的数据知道 Chunk 对应的最新版本,Master 节点会整合具有最新版本 Chunk 的服务器。每个 Chunk 服务器会记住本地存储 Chunk 对应的版本号,当 Chunk 服务器向 Master 汇报时,就可以说,我有这个 Chunk 的这个版本。而 Master 节点就可以忽略哪些版本号与已知版本不匹配的 Chunk 服务器。
”
❓primary chunk 有什么用?
控制流的顺序由其决定,租约期限内决定其他副本写入 chunk 顺序,避免同时副本写入的顺序不对。依然还是控制流的主备关系,client 还是正常发送所有的数据给副本,只是主备关系决定了写入的顺序。
🤔GFS 读写流程
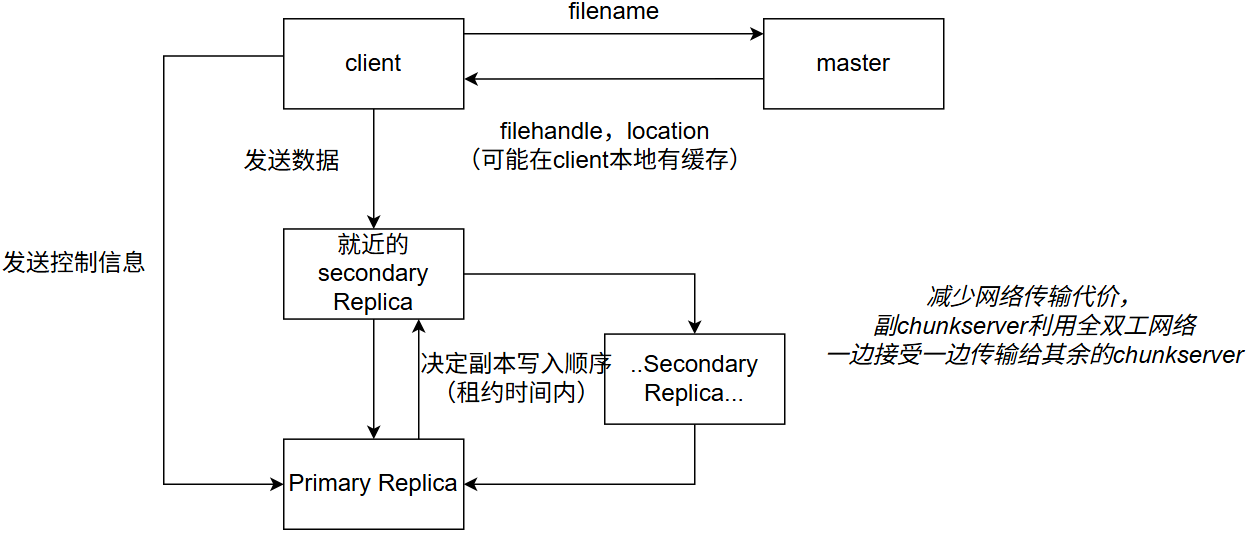
流水线式数据传输可以节省大量的网络传输,不用再从客户端指定传输到主 chunkserver,那样的话主 chunkserver 需要给多个 replica 发送数据,网络带宽将成为性能瓶颈。控制流分离,client 仍然需要向主 chunkserver 发送写入顺序信息,等待所有副本接收到数据后,主 chunk server 决定顺序写入。
推荐使用追加的方式写入文件,也是 GFS 在文件写入可以接受 “重复写入数据,但是数据不能错误” 的想法。
🤔 那么一致性模型的要点是什么呢?

如果是全局的改写,一次修改可能涉及到多个 chunk,GFS 并没有全局 chunk 的概念,只能保证相同 chunk 副本之间的写入是一致的(这是由数据流和控制流分离保证的,控制流决定了写入的顺序,在上面已经有介绍);而在多个改写的 chunk 之间,并发的写操作对不同的 chunk 来自 S1 S2 S3 可能不同。不同 chunk 对改写的顺序不能保证相同

优点很明显:1. 减少内存占用空间,大部分 chunk 并不会修改,快照和原文件的 chunk 是公用的;2. 快速的快照机制,停止写入的时间很短暂,因为只需要将源数据拷贝给快照文件,增加引用计数即可
GFS 一些课堂问题
可不可以通过版本号来判断副本是否有之前追加的数据?
Robert 教授:所有的 Secondary 都有相同的版本号。版本号只会在 Master 指定一个新 Primary 时才会改变。通常只有在原 Primary 发生故障了,才会指定一个新的 Primary。所以,副本(参与写操作的 Primary 和 Secondary)都有相同的版本号,你没法通过版本号来判断它们是否一样,或许它们就是不一样的(取决于数据追加成功与否)。
这么做的理由是,当 Primary 回复“no”给客户端时,客户端知道写入失败了,之后客户端的 GFS 库会重新发起追加数据的请求,直到最后成功追加数据。成功了之后,追加的数据会在所有的副本中相同位置存在。在那之前,追加的数据只会在部分副本中存在。(注:挂掉的副本没有接收到数据,master 也可以通过 checksum 来判断)
总结:版本号不是判断写入是否成功的工具,版本号是用来区分是否错过了换主,通过检查内容/校验等方式以及比较版本标记哪些 chunk 是陈旧的。 😁 客户端重试,并且期望之后能正常工作。并不会立即解决错误的问题
如果 Secondary 服务器挂了,Master 节点可以发现并更新 Primary 和 Secondary 的集合,之后再增加版本号。但是这些都是之后才会发生
如果 master 发现 primary 挂了怎么办?
Robert 教授:可以这么回答这个问题。在某个时间点,Master 指定了一个 Primary,之后 Master 会一直通过定期的 ping 来检查它是否还存活。因为如果它挂了,Master 需要选择一个新的 Primary。Master 发送了一些 ping 给 Primary,并且 Primary 没有回应,你可能会认为 Master 会在那个时间立刻指定一个新的 Primary。但事实是,这是一个错误的想法。为什么是一个错误的想法呢?因为可能是网络的原因导致 ping 没有成功,所以有可能 Primary 还活着,但是网络的原因导致 ping 失败了。❗ 但同时,Primary 还可以与客户端交互,如果 Master 为 Chunk 指定了一个新的 Primary,那么就会同时有两个 Primary 处理写请求,这两个 Primary 不知道彼此的存在,会分别处理不同的写请求,最终会导致有两个不同的数据拷贝。这被称为脑裂(split-brain)。
脑裂是一种非常重要的概念,我们会在之后的课程中再次介绍它(详见 6.1),它通常是由网络分区引起的。比如说,Master 无法与 Primary 通信,但是 Primary 又可以与客户端通信,这就是一种网络分区问题。网络故障是这类分布式存储系统中最难处理的问题之一。
所以,我们想要避免错误的为同一个 Chunk 指定两个 Primary 的可能性。Master 采取的方式是,当指定一个 Primary 时,为它分配一个租约,Primary 只在租约内有效。Master 和 Primary 都会知道并记住租约有多长,当租约过期了,Primary 会停止响应客户端请求,它会忽略或者拒绝客户端请求。 因此,如果 Master 不能与 Primary 通信,并且想要指定一个新的 Primary 时,Master 会等到前一个 Primary 的租约到期。这意味着,Master 什么也不会做,只是等待租约到期。租约到期之后,可以确保旧的 Primary 停止了它的角色,这时 Master 可以安全的指定一个新的 Primary 而不用担心出现这种可怕的脑裂的情况。
为什么立即指定一个新的 Primary 是坏的设计?
因为客户端会通过缓存提高效率,客户端会在短时间缓存 Primary 的身份信息(这样,客户端就不用每次都会向 Master 请求 Primary 信息)。即使没有缓存,也可能出现这种情况,客户端向 Master 节点查询 Primary 信息,Master 会将 Primary 信息返回,这条消息在网络中传播。之后 Master 如果发现 Primary 出现故障,并且立刻指定一个新的 Primary,同时向新的 Primary 发消息说,你是 Primary。Master 节点之后会向其他查询 Primary 的客户端返回这个新的 Primary。而前一个 Primary 的查询还在传递过程中,前一个客户端收到的还是旧的 Primary 的信息。如果没有其他的更聪明的一些机制,前一个客户端是没办法知道收到的 Primary 已经过时了。 如果前一个客户端执行写文件,那么就会与后来的客户端产生两个冲突的副本。